Spark
The Spark task type allows you to utilize the power of the Apache Spark data processing engine as part of Loome Integrate jobs.
This currently is facilitated over a Livy connection, the Spark task type supporting all available Spark processing methods including pre-compiled JAR files and PySpark enabled Python scripts.
How to Create a Spark Task
Create a new task.
Provide a name to identify this task and then choose the agent that will run this task.
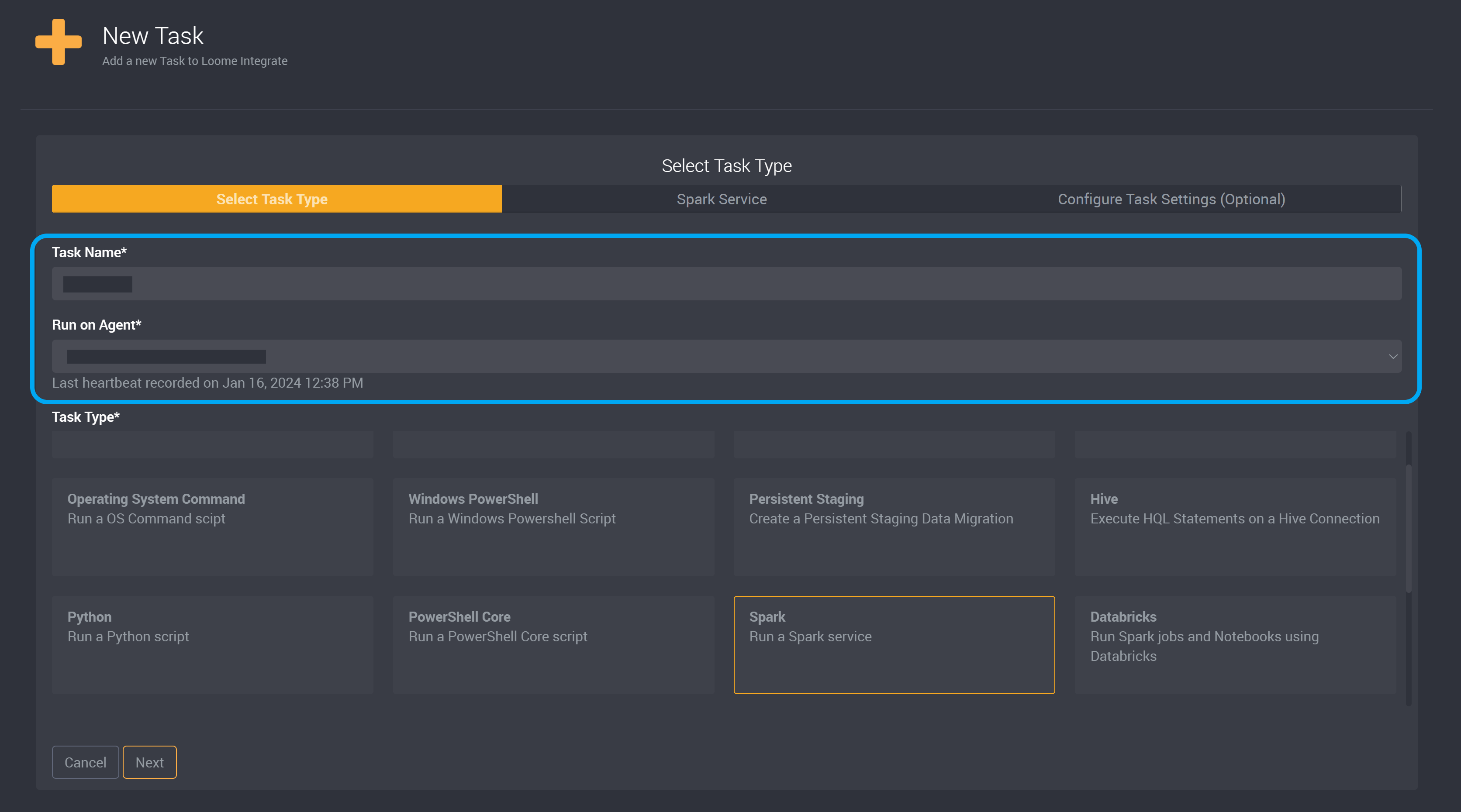
Choose Spark as the task type.
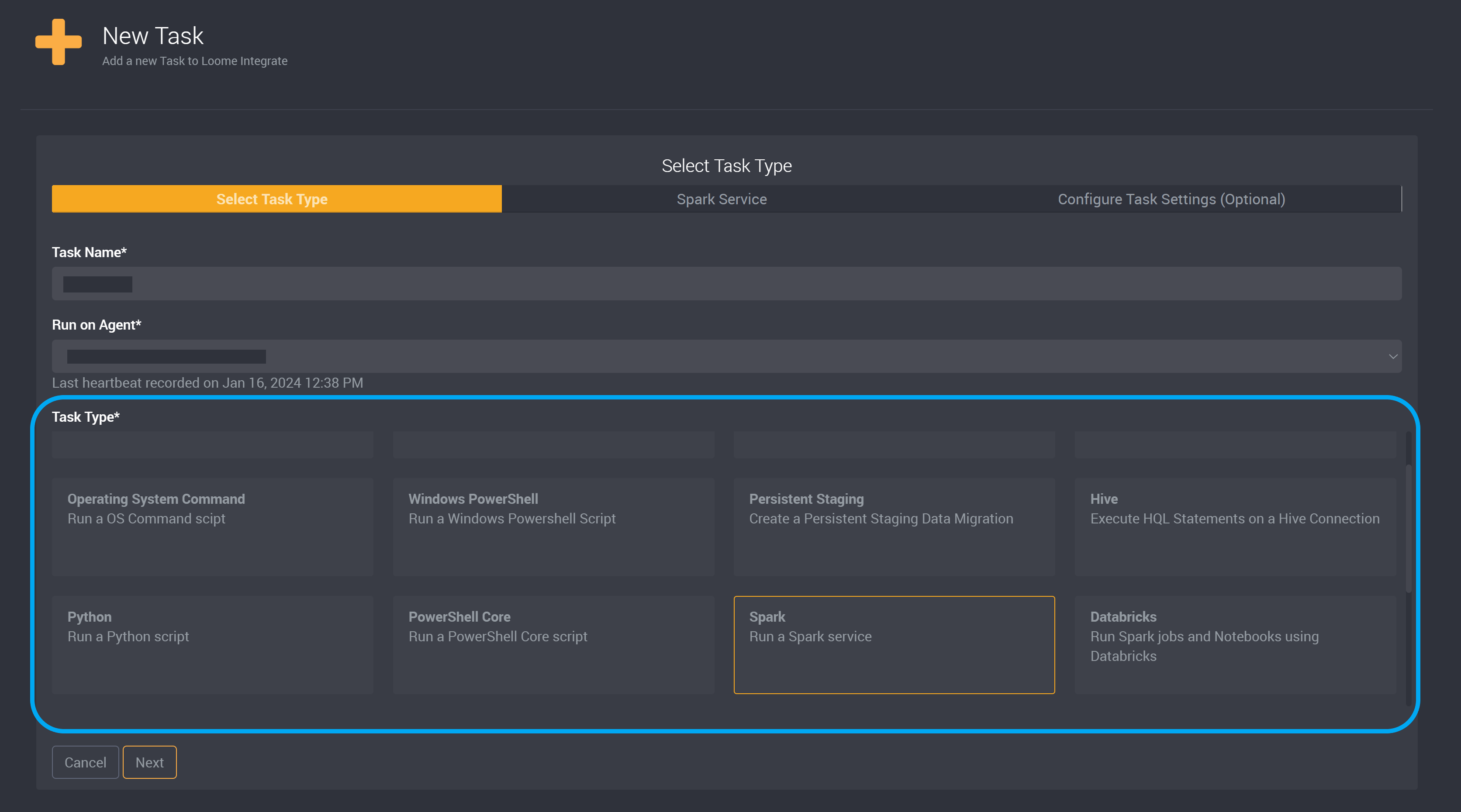
Click Next at the bottom of this page to move on to the next page.
The Source Connection dropdown will provide all available Livy connections.
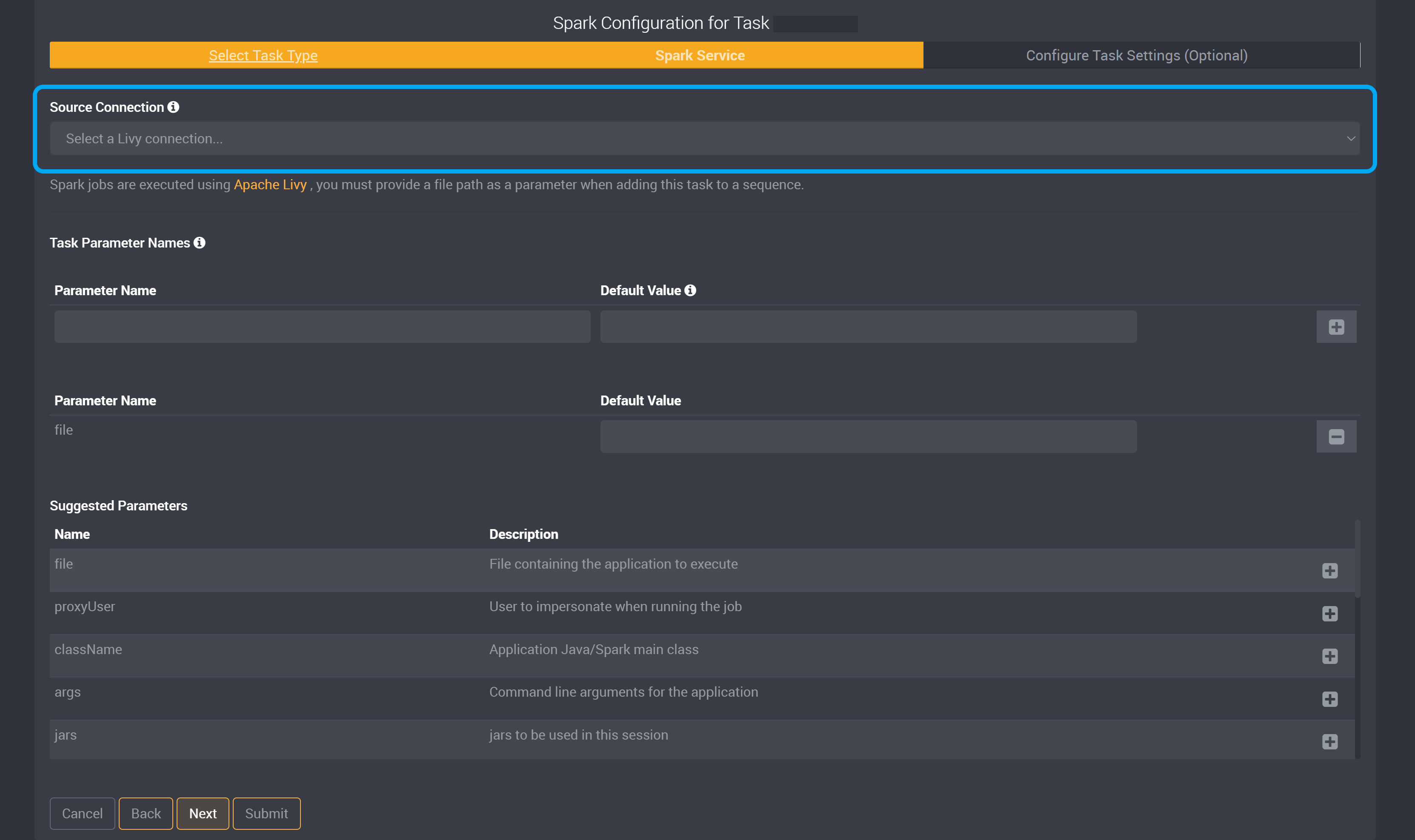
Selecting the Spark Parameters
The Spark task is similar to the Databricks task not only in the type of work it can do but also in its utilization. For Spark tasks you use the task builder to select the parameters you wish to use and then set those parameters when you sequence the task in the job.
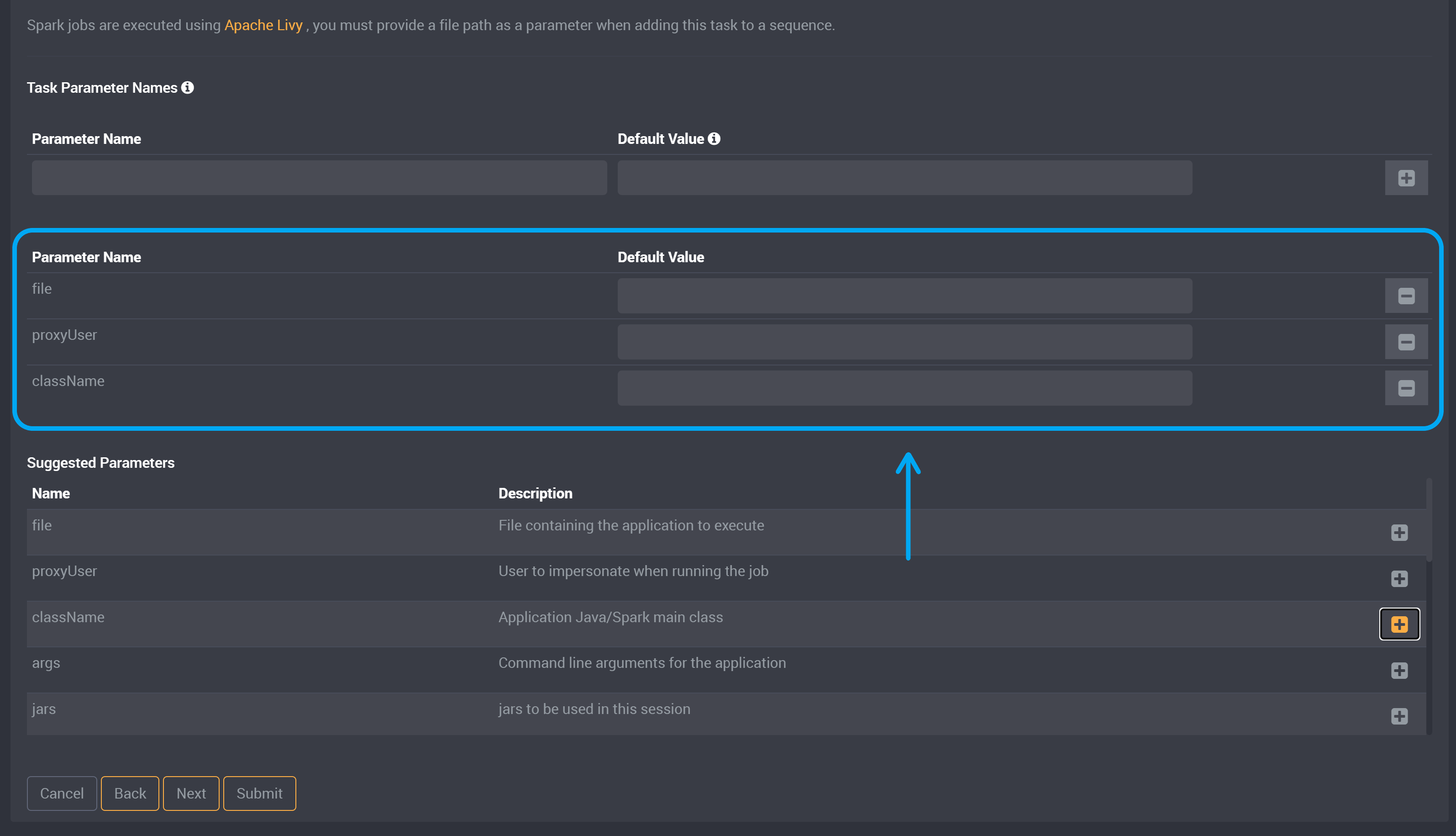
Spark jobs are executed using Apache Livy, you must provide a file path as a parameter when adding this task to a sequence.
We have provided suggested parameters below. Each suggested parameter provides a description of what it is used for beside it.
Click on the ‘+’ button beside a parameter to add it to the task.
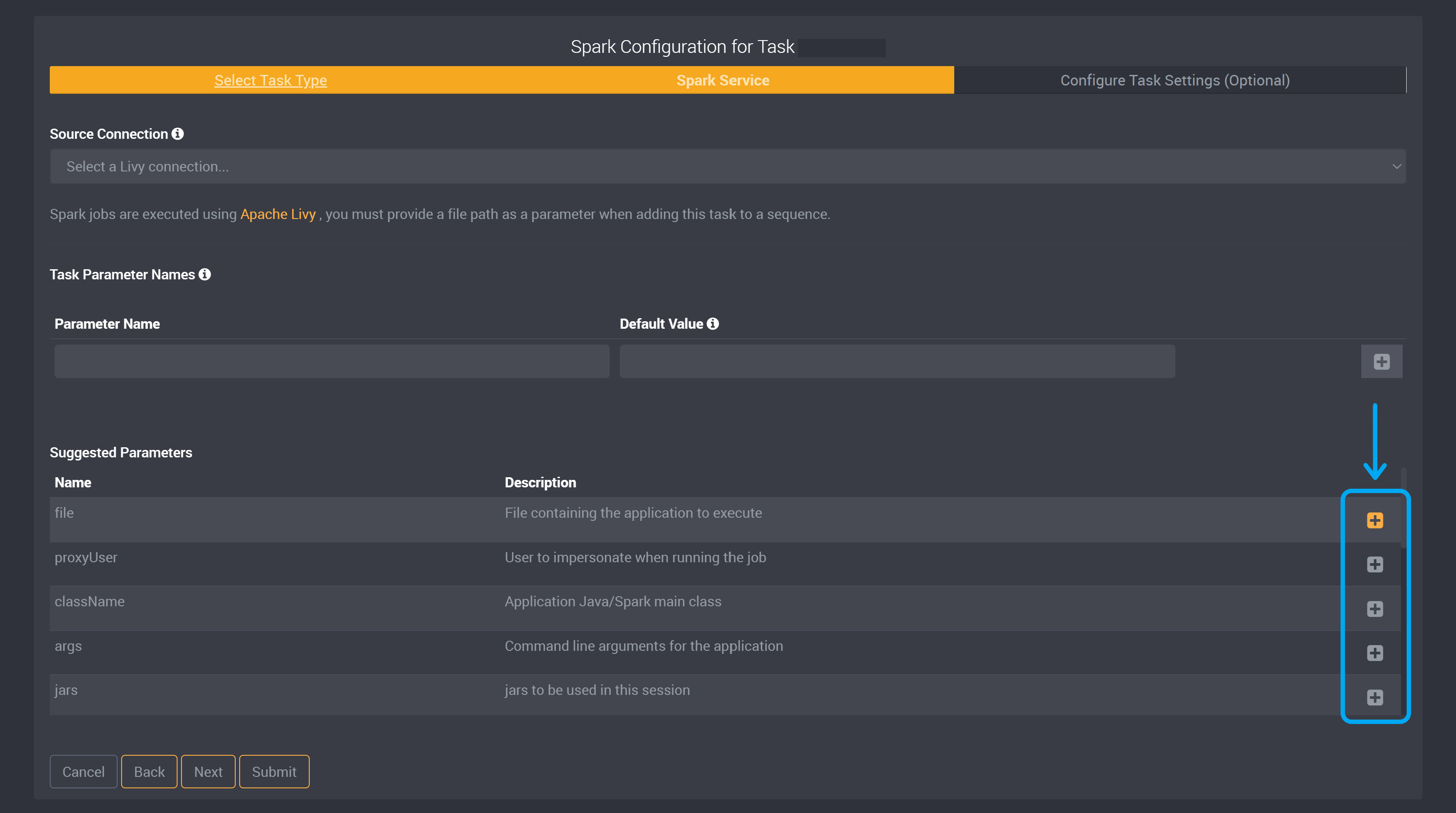
You can then optionally provide a default value for this parameter after it has been added to the task parameter section.
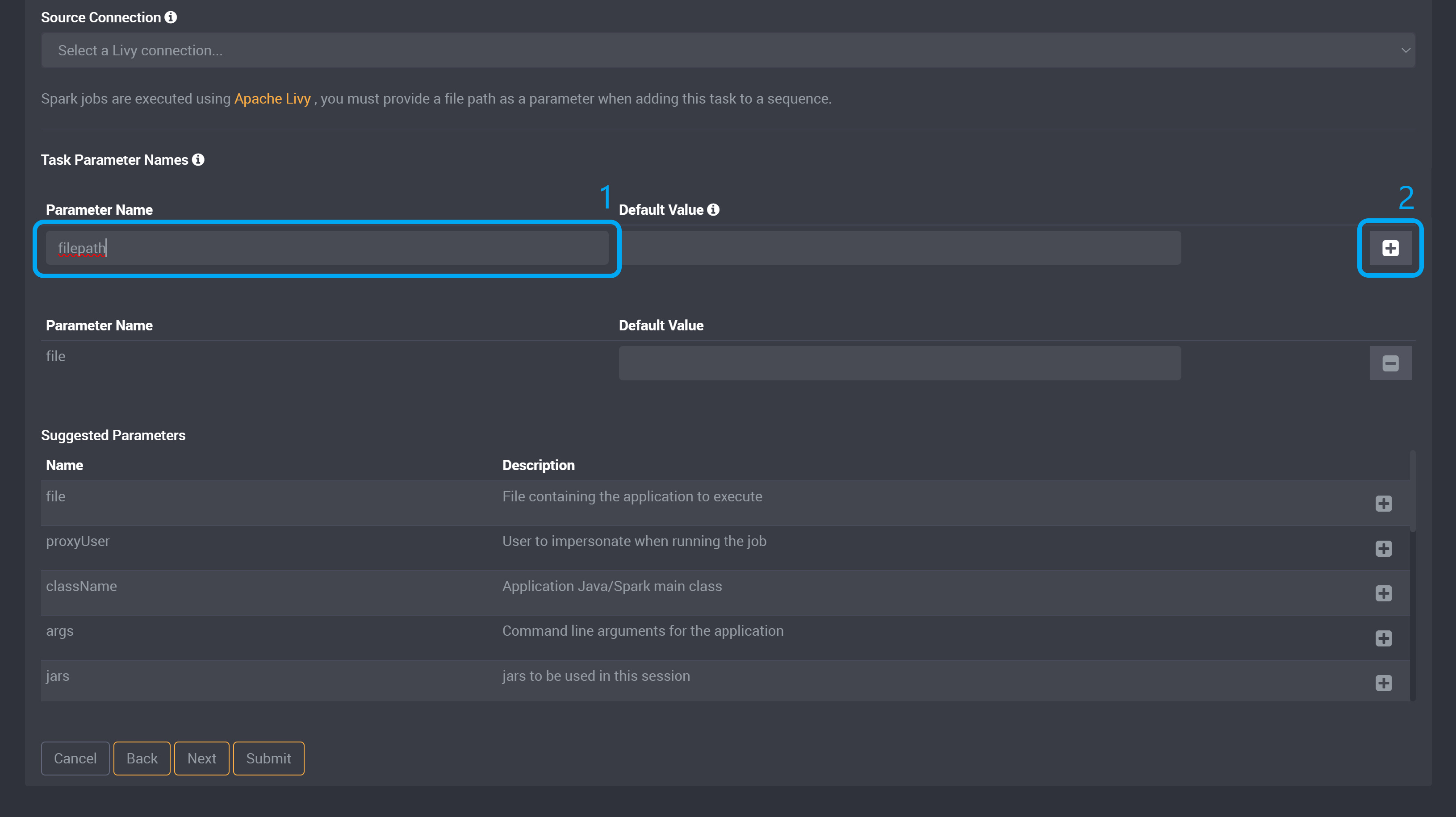
You can also provide custom parameters, by providing a parameter name and default value (optional) in the fields under the Task Parameter Names section above.
You will need to provide a parameter called filepath to later add a value when adding this task to a sequence after you have submitted this task. The default value is optional so you do not need to provide a value here. Type in filepath and click Add.
After providing your parameters, you can Submit this task to save.
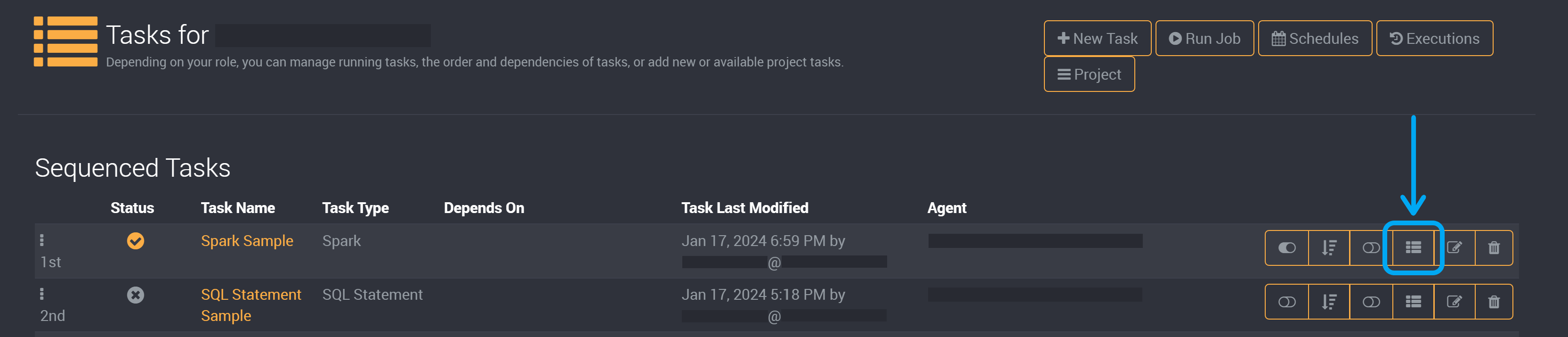
You will need to add a value when adding this task to a sequence now that you have submitted this task.
On the job page, click on Edit Parameter Values.
Beside the parameter ‘filepath’, provide a value.
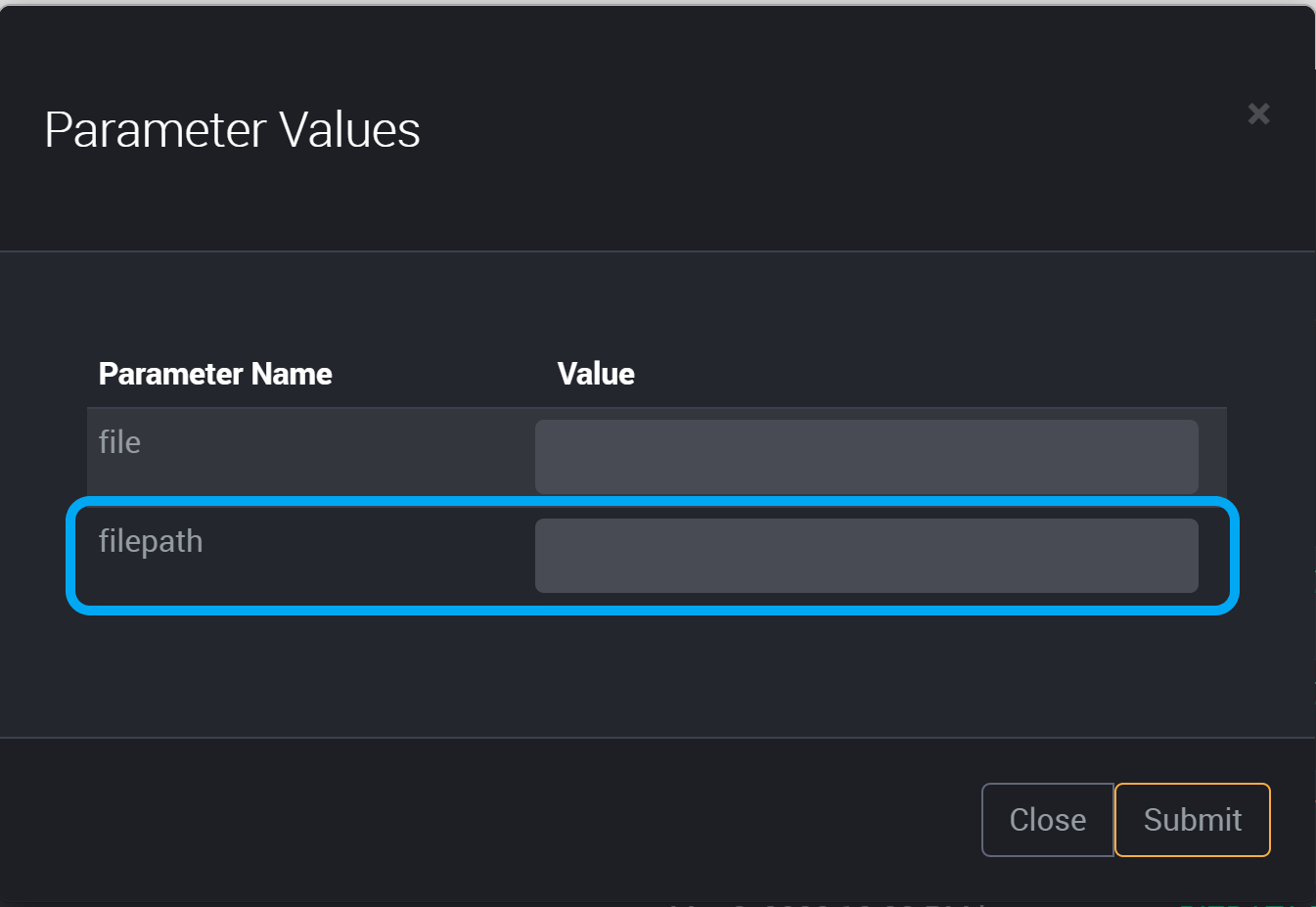
Click Submit to save this parameter.