Spark SQL Statement
The Spark SQL Statement task executes a Spark SQL script on a Spark enabled connection.
As is the case with the SQL Statement task, this task does not show output and is intended for creating and modifying database tables.
Currently the Spark SQL Statement task type only supports execution on Databricks connections. For general Hadoop Spark invocation use the Spark task type.
How to Create a Spark SQL Statement Task
Create a new task.
Provide a name to identify this task and choose an agent from the dropdown.
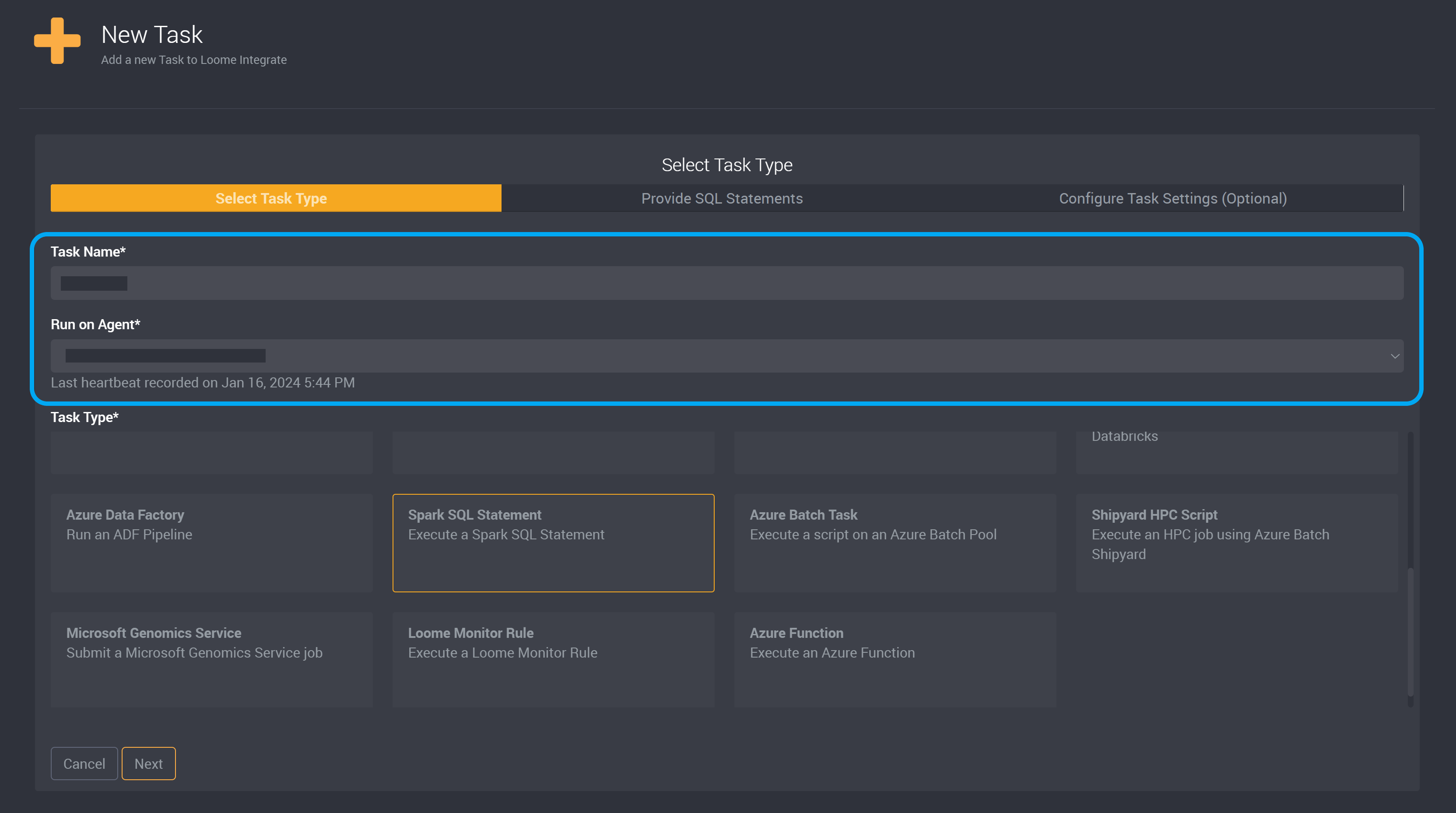
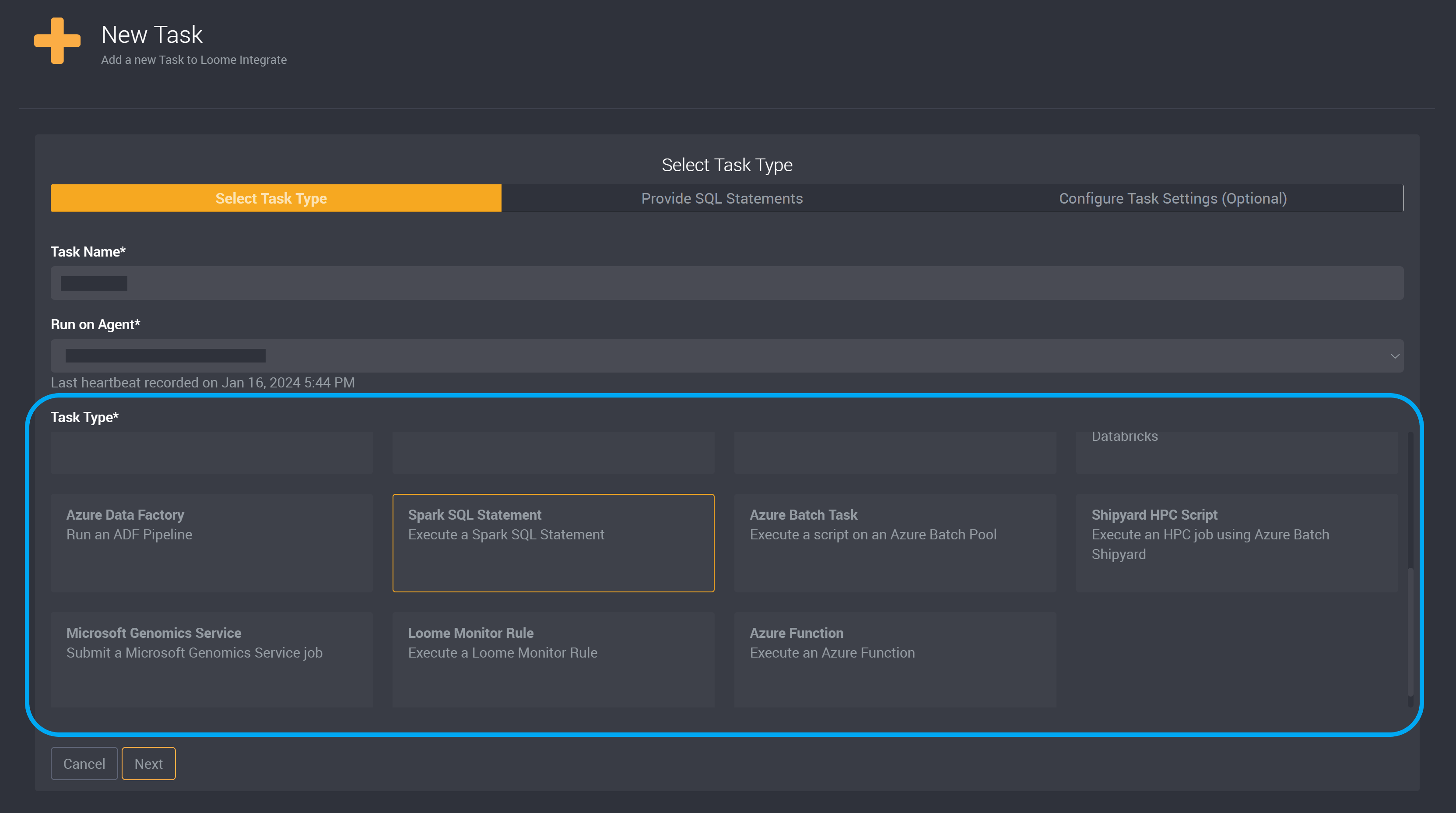
Choose Spark SQL Statement as the task type.
Provide Spark SQL Statement
Once the Spark SQL task type is selected, all that’s required for the Spark SQL task is a valid connection and the statement to run.
Choose a source connection.
For Databricks connections you will be required to select the cluster definition or existing cluster to use for the statement.
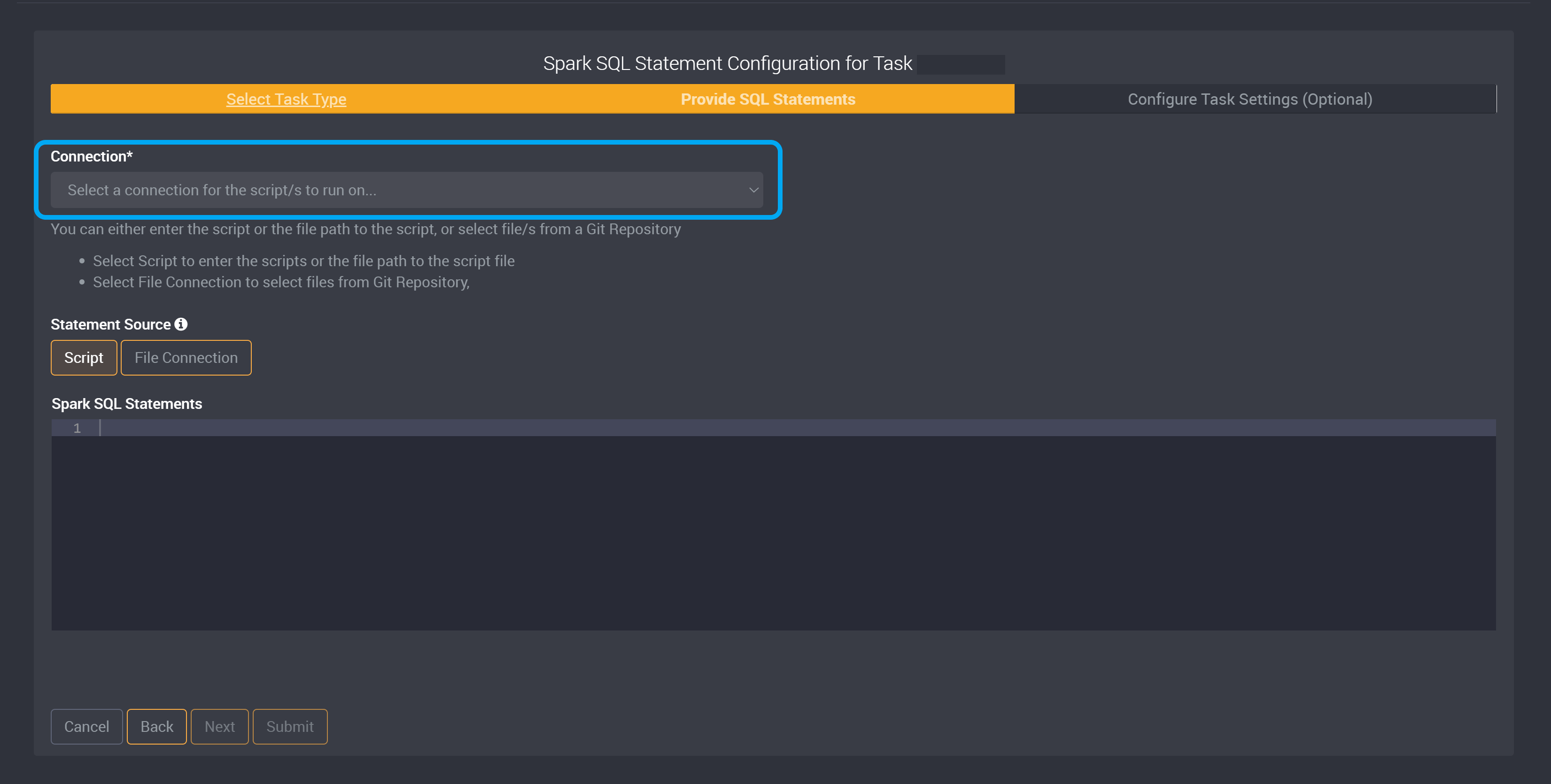
In this next section, you can then either enter the script, the file path to the script, or select file/s from a Git Repository.
The task type accepts any valid Spark SQL statement, and will submit the statement as part of the task.
Currently a Spark SQL Statement does not have the ability to be validated so Loome Integrate cannot check the syntax of your statements.
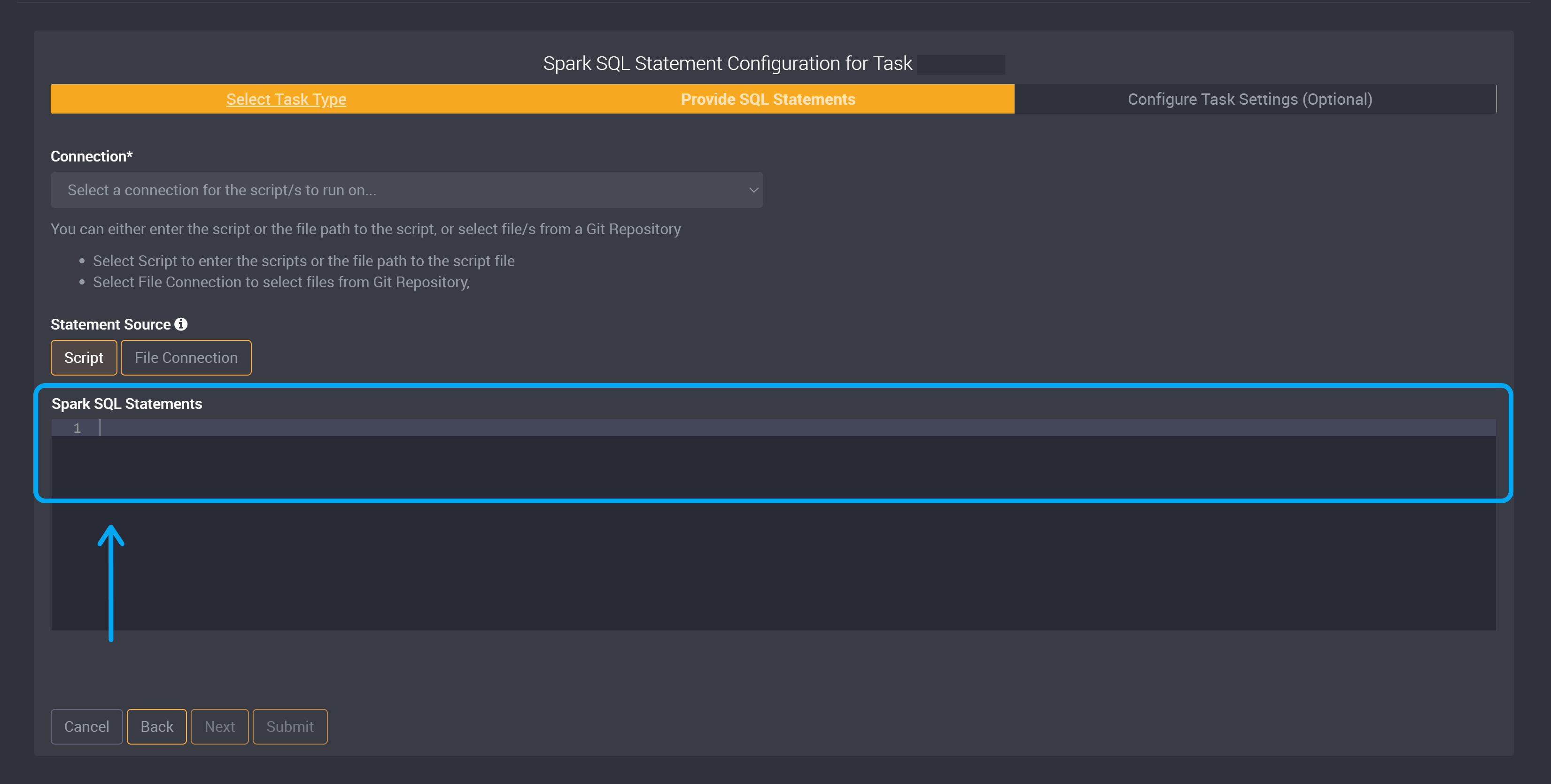
Choose whether the Statement Source will be a script or file connection.
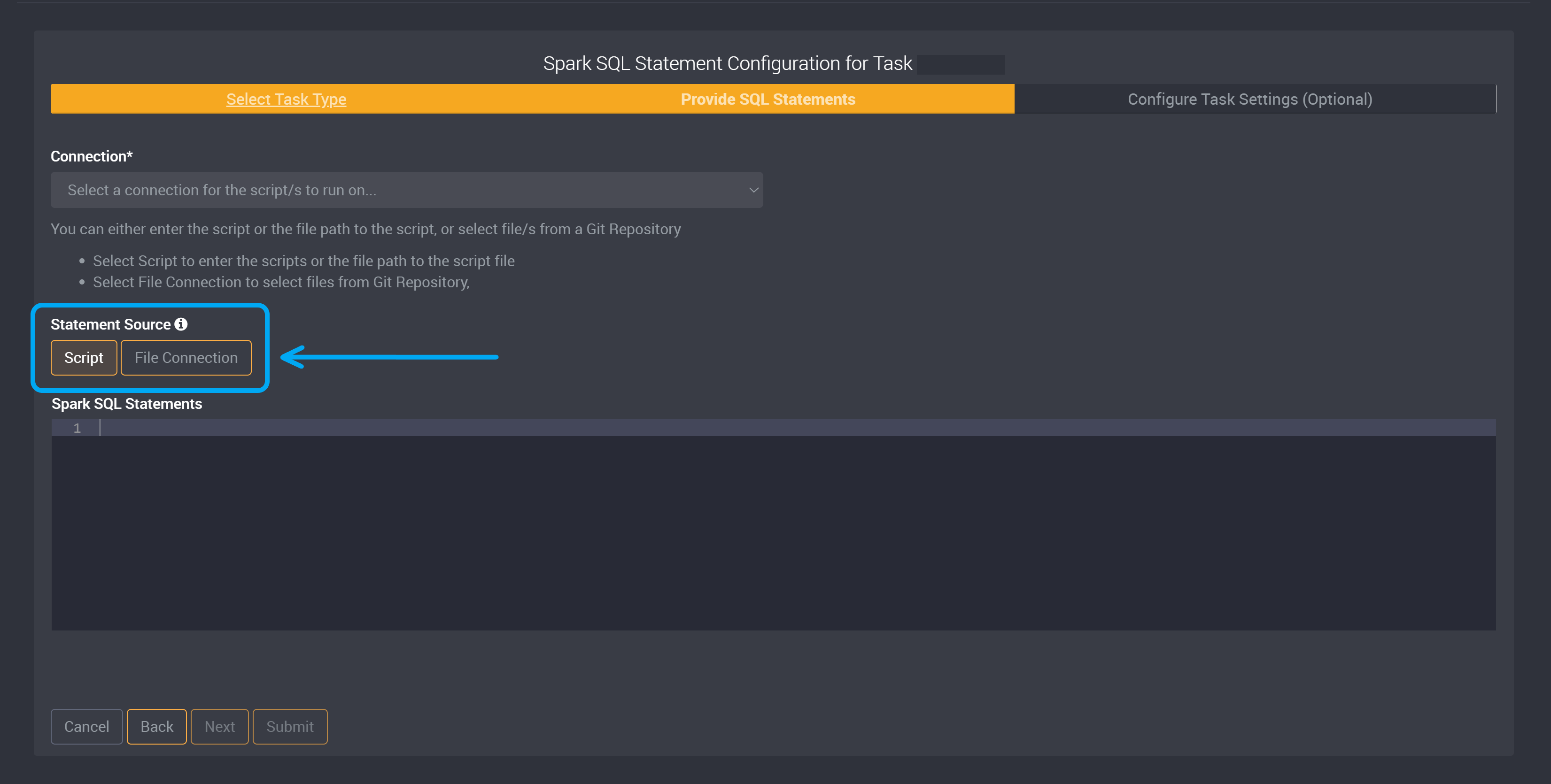
If you chose Script, provide your Spark SQL Statement script or the file path to the script file in the Spark SQL Statements field.
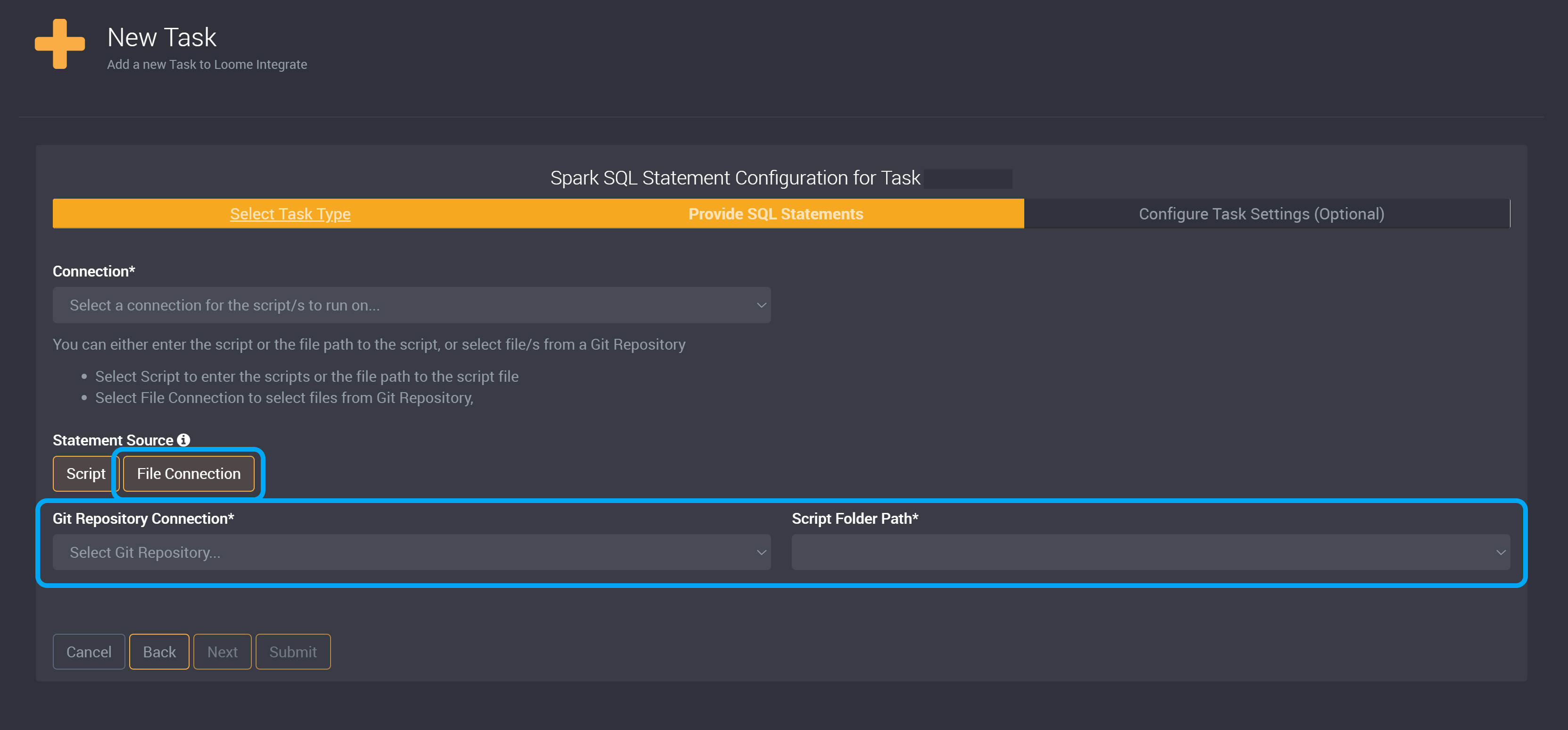
If you chose File Connection, choose your Git Repository from the dropdown and provide your Script Folder Path to select files from a Git Repository.
You can enable a setting for this task to run scripts in parallel. This will allow the Loome Integrate agent to execute multiple scripts in parallel, rather than in sequence. Learn more here.