Persistent Staging
Overview
- What is Persistent Staging
- How to Create a Persistent Staging Task
- Edit your Persistent Staging Task
- What is Created by a Persistent Staging Task
What is Persistent Staging?
When Persistent Staging is used in a data migration, any changes to data is persisted between migrations, and you will be provided with a complete audit log of the persisted data.
This means that with each persistent staging migration, when data is changed or modified, Loome Integrate will keep both a record of the time that the data was in a particular state and will also insert a new data record that will show the current state of the data.
This is facilitated by a table and view:
| View | Description |
|---|---|
| History | This view is a history of your data that has been recorded in your database by persistent staging. |
| Current | This table is the current state of your data in your target and this table should be the same as the data in the source. |
This allows for immutable extract and load.
LoadDateTime and StartTime fields will be stored in UTC format in your database.
You can also use both incremental and persistent staging in a data migration task, but please note that it will take away part of the functionality of persistent staging. Incremental will only load recently modified records. The records that persistent staging will keep a history of will not be persisted unless they are included in the selected incremental staging time period. So if you decide to use persistent staging with incremental staging, you will only persist the data in the time period you have defined.
How to Create a Persistent Staging Task
Create a new task and select Persistent Staging as your task type.
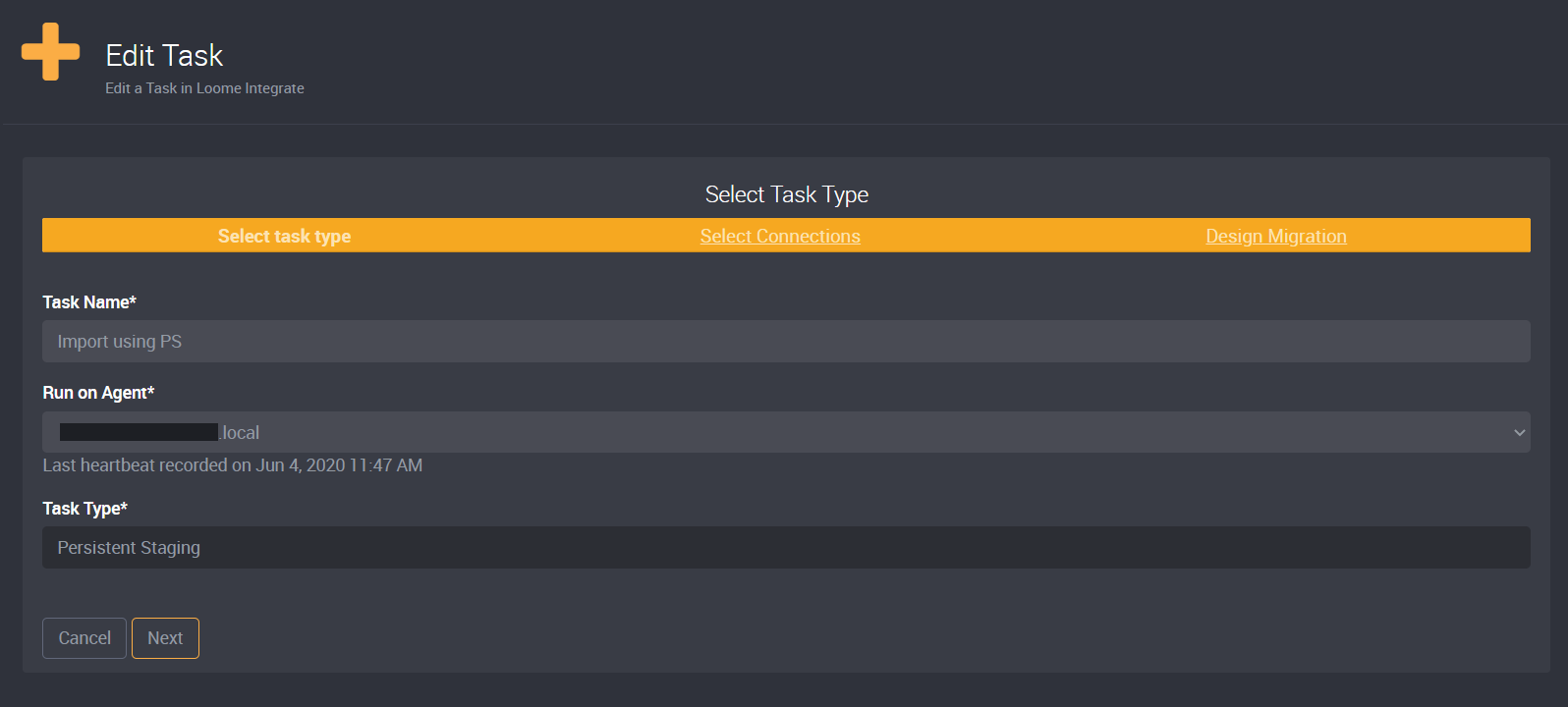
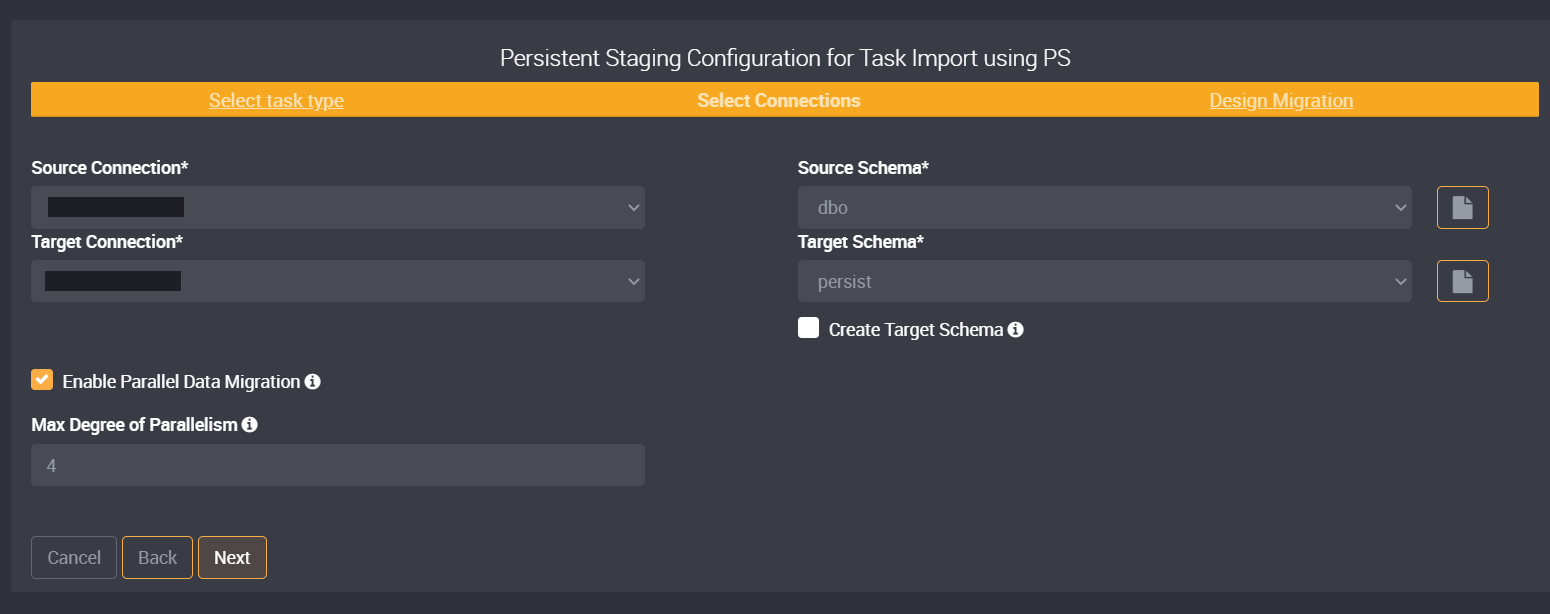
Select your Source Connection and Target Connection. For the example in the following image, I have selected SQL Server for the source and target.
Choose the Source Tables that you would like to extract and load into your target using persistent staging. Click on the ‘+’ beside each table.
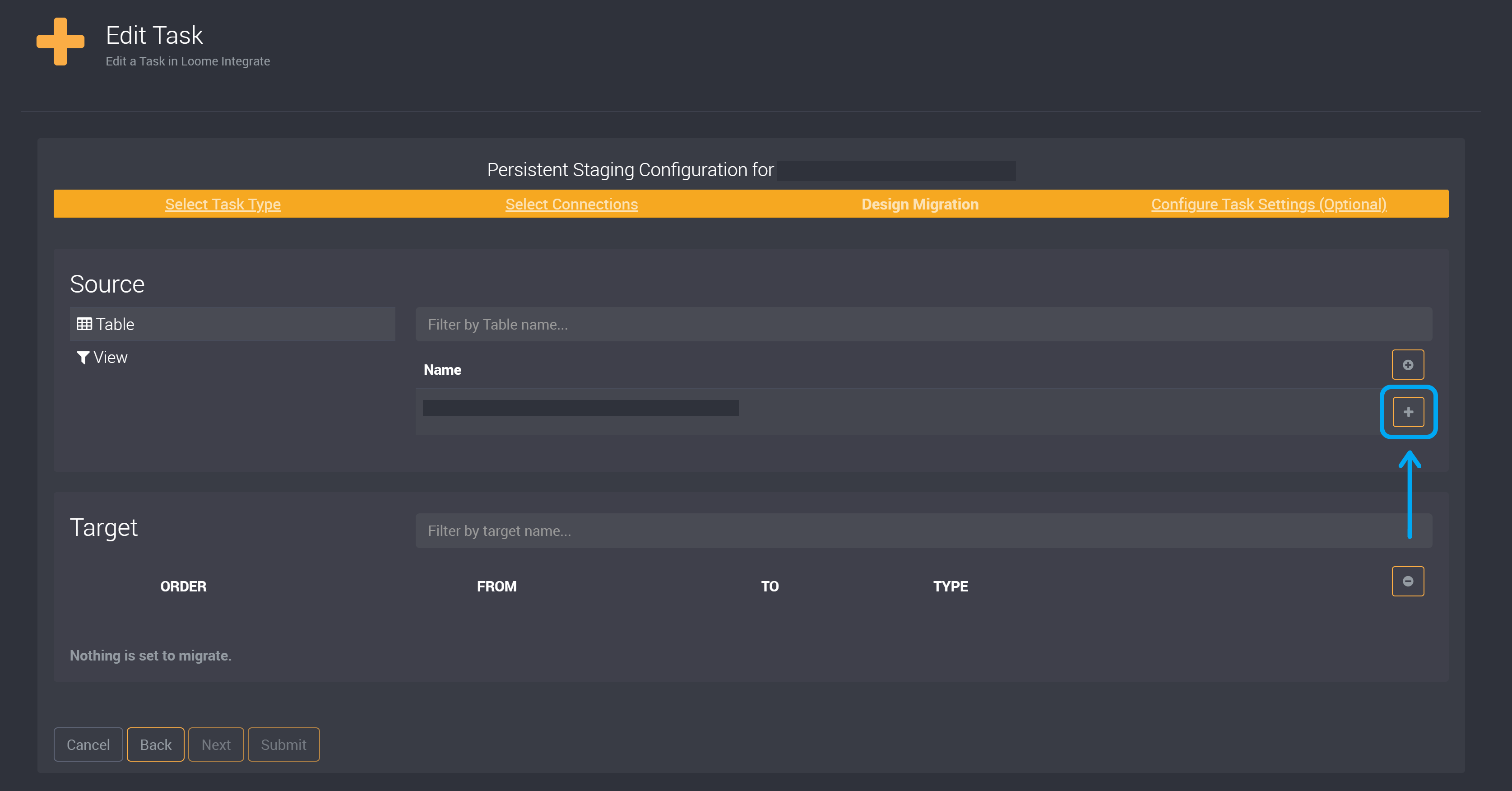
In the image below, I have chosen one table and it has moved into the target section.
Choose your Persistent Staging Options
Click on the Persistent Staging button beside your selected table in the target section.
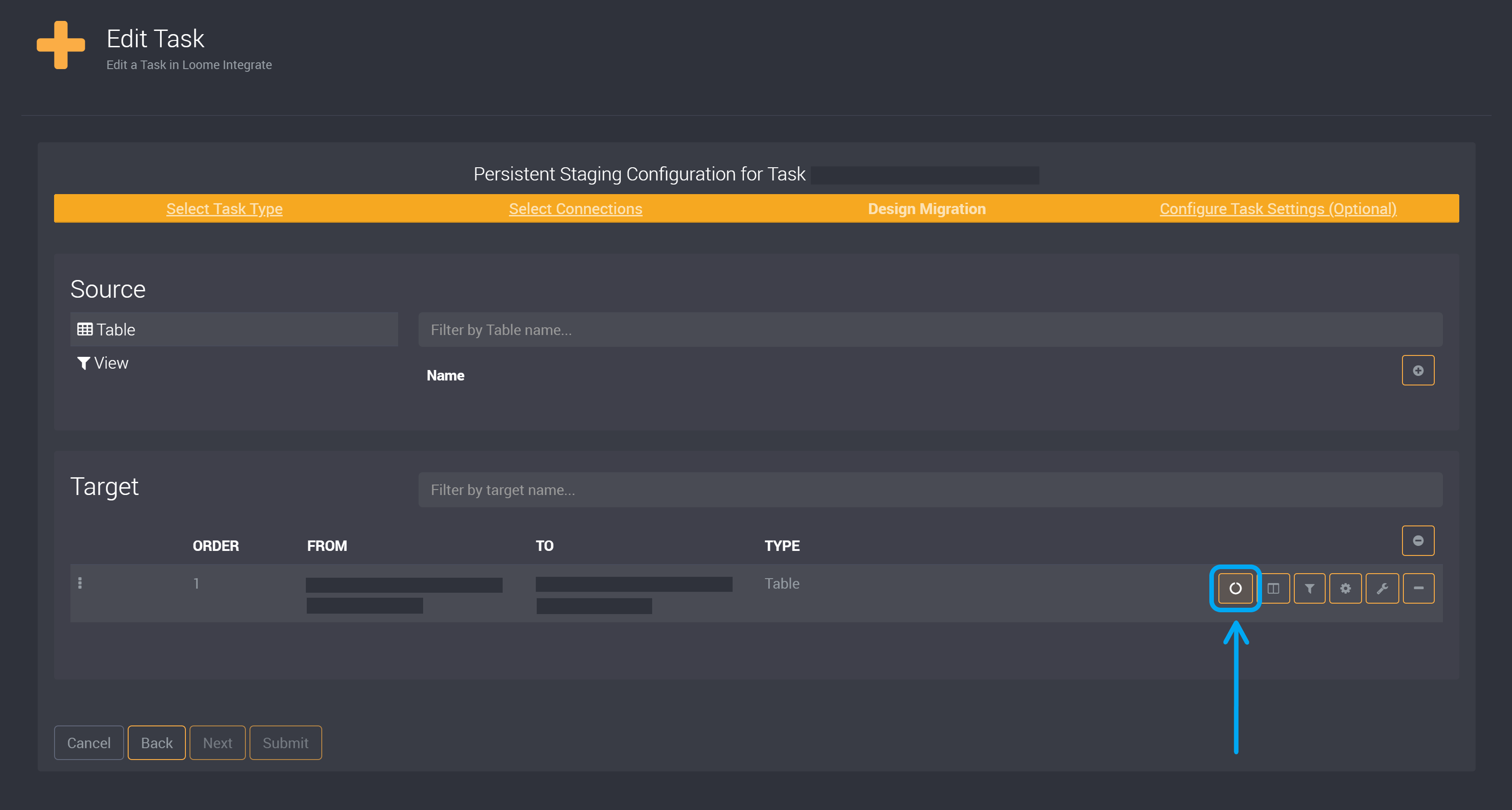
You will need to select a key column and you can also choose to ignore any columns. We strongly recommend you use the LoadDateTime date column that is selected by default.
Date Column
Persistent staging uses a date column. Loome Integrate will use the ‘LoadDateTime’ column by default and it is set to the time the task is run and is generated by Loome.
The ‘Date Column’ behaves like a posted date and is never updated, so we highly recommend that you use ‘LoadDateTime’ as the date column.
If you select a different column, you must ensure its consistency. Irregularities in the date column data will most likely cause data issues in your persistent staging task. Due to the high potential for issues, we suggest ‘LoadDateTime’ remains the selected date column.
Key Column (Required)
Select your key column, which Loome Integrate will use as the unique identifier for persisted records.
A key column is required in persistent staging. It must be a column that has a unique value in every row.
You must select at least one column as a key column. This will be used to persistently stage data in other columns. This also means you must leave at least one column deselected so that your data can be persistently staged.
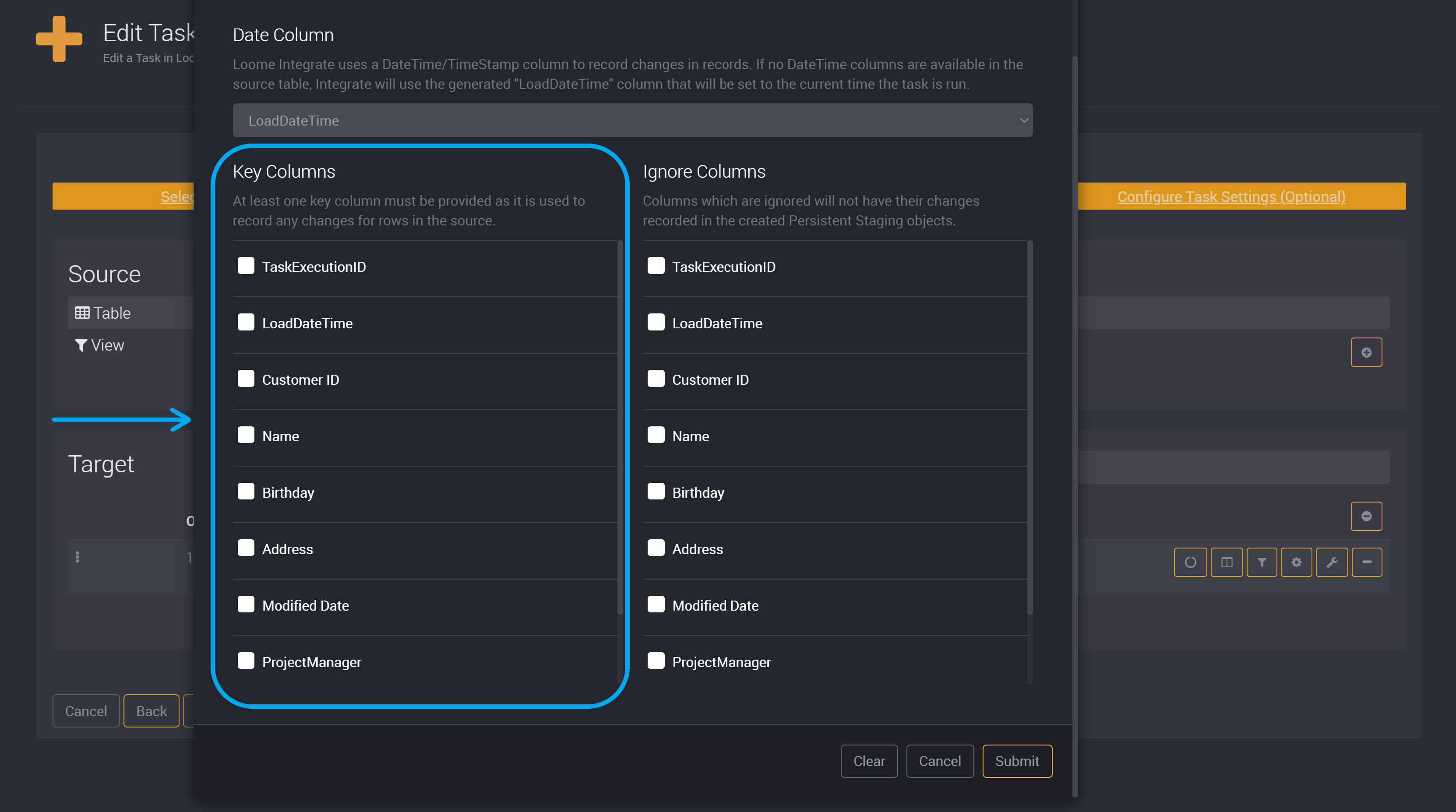
Click on Submit or if there are columns you would like to ignore, choose ignored columns.
Ignored Columns (Optional)
You can also choose to ignore columns for persistent staging. Choose the column you would like to ignore on the right under Ignore Columns.
If a column is ignored, its changes will not be recorded in the created persistent staging object.
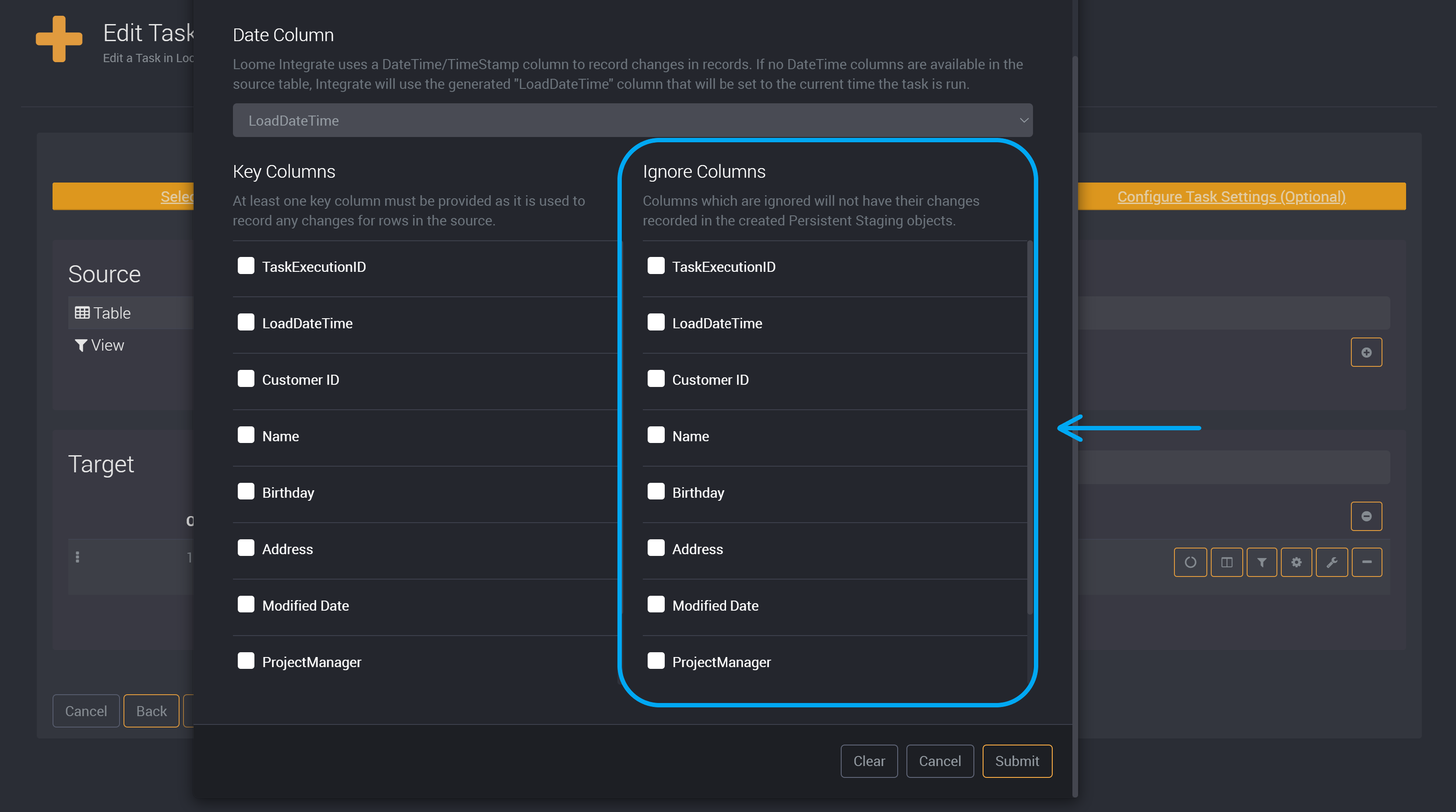
Click on Submit.
Submit Task
Submit the task and you can either run it right away or create a schedule that will cause it to run at a time and day you have chosen.
You can also choose to click Next to view the task settings and modify any settings that will apply only to this task.
Please note that tasks that use a SQL connection as a target connection will use clustered indexes. If you choose any individual key column size that exceeds 900 bytes or if the sum of all key column sizes exceed 2600 bytes, you will need to confirm your key column selection as these columns can cause your data to be truncated.
If you change your selected key column after you have run a task, any existing data in the target table will be archived when the task is run on the next execution. Archived tables will include the date it was archived in the table name. The newly created tables will continue to be created under the task name.
Edit your Persistent Staging Task
Change a Key Column
If you change the key column, the Loome agent will archive the persistent staging table and its corresponding clustered index.
The archived table will be named in the following format ‘
You will also be asked to confirm that you would like to update the key column, as this change will cause your current output table to be archived on the next execution of this persistent staging task.
Added Columns
When you add a new column to the business key or to the columns that are persistently staged, the next time this task runs the agent will add the new columns to the persistent staging tables and history view.
It will also recreate the Current table and Hash view based on the revised definition.
The agent will also calculate a new RowHash for every business key that has not been flagged as deleted in the Current table, and will add a new row for each of these business keys to the persistent staging table.
Please note that our Data Migration and Persistent Staging tasks use UTC times. LoadDateTime fields will now come through as UTC. This may cause a scenario where records loaded after you update the agent may appear before existing rows in your persistent staging output. Find the conditions that causes this scenario when you update your Loome Agent in our release notes here.
Delete Columns
You can remove a column from a persistent staging table and on the next execution the agent will post NULL to the removed column.
It will also recreate the Current table and Hash view based on your revised definition. The Loome agent will calculate a new RowHash for every business key that has not been flagged as deleted in the Current table and it will add a new row for each of these business keys to the persistent staging table.
If you add a column that was previously removed, on the next execution the agent will post the source value to the reinstated column. It will also again recreate the Current table and Hash view based on the revised definition, and will calculate a new RowHash for every business key that has not been flagged as deleted in the Current table and add a new row for each of these business keys to the persistent staging table.
Modify Column Data Types
You can modify a column definition in your source and it will be reflected in your persistent staging table, but this depends on what is allowed in your chosen source and target connections.
Depending on your selected connections, if you change the definition of a column in a persistent staging source, such that it encompasses the previous definition, e.g. varchar(20) to varchar(50), smallint to int, or date to datetime2, the persistent staging task will account for these changes and will modify the target column when the task is run.
On the next execution, the agent will change the column definition in the persistent staging table and will recreate the Current table, History view and Hash view. The agent will calculate a new RowHash for every business key that has not been flagged as deleted in the Current table, and where the RowHash has changed (e.g., when changing from date to datetime2), the agent will add a new row for each of these business keys to the persistent staging table.
Please note that the modification of column definitions is limited to what changes are allowed by the selected connections.
For example, in a persistent staging task that targets Azure Synapse SQL you cannot change ‘Varchar’ to ‘Varbinary’.
Similarly, in a persistent staging task that is targeting Snowflake Data Warehouse, you cannot change the ‘int’ column type into ‘Varchar(50)’ as they are different data types, but you can change a similar data type such as ‘int’ to ‘numeric’. You cannot decrease the column size of ‘Varchar(50)’, but you can increase the column size ‘Varchar(50)’ to ‘Varchar(100)’. You can also increase and decrease the precision of a number column.
What is Created using a Persistent Staging Task
If we were targeting a schema of TargetSchema and a table of TableName the following objects would be created.
Persistent Staging Objects:
[TargetSchema].[TableNameSource]
- This is a table that contains all imported records for this task’s persistent staging history
- If records are modified and then persisted, there will be duplicates of the record with a different
PersistSourcesKeyvalue - This table will use a clustered index to improve performance on SQL Server and Snowflake.
[TargetSchema].[TableNameCurrent]
- This is a table that exposes the current state of the source table
- The results included are all the records in the source table that do not have an end date
- This table will use a clustered index to improve performance on SQL Server and Snowflake.
[TargetSchema].[TableNameHistory]
- This is a view that exposes the history of all records in the source table
- Each record’s history is grouped by its key columns and ordered from oldest to current