Reconciliation
Reconciliation checks for differences between two data sets.
You can compare two data sets in one rule, and view them both in the one results table to see highlighted mismatches and orphan records from each data set.
You can follow our guide for creating a rule using source data but you will also need to provide a connection for both your source and comparison data sets, as well a query for each. The column names and data types will also need to match.
Connections
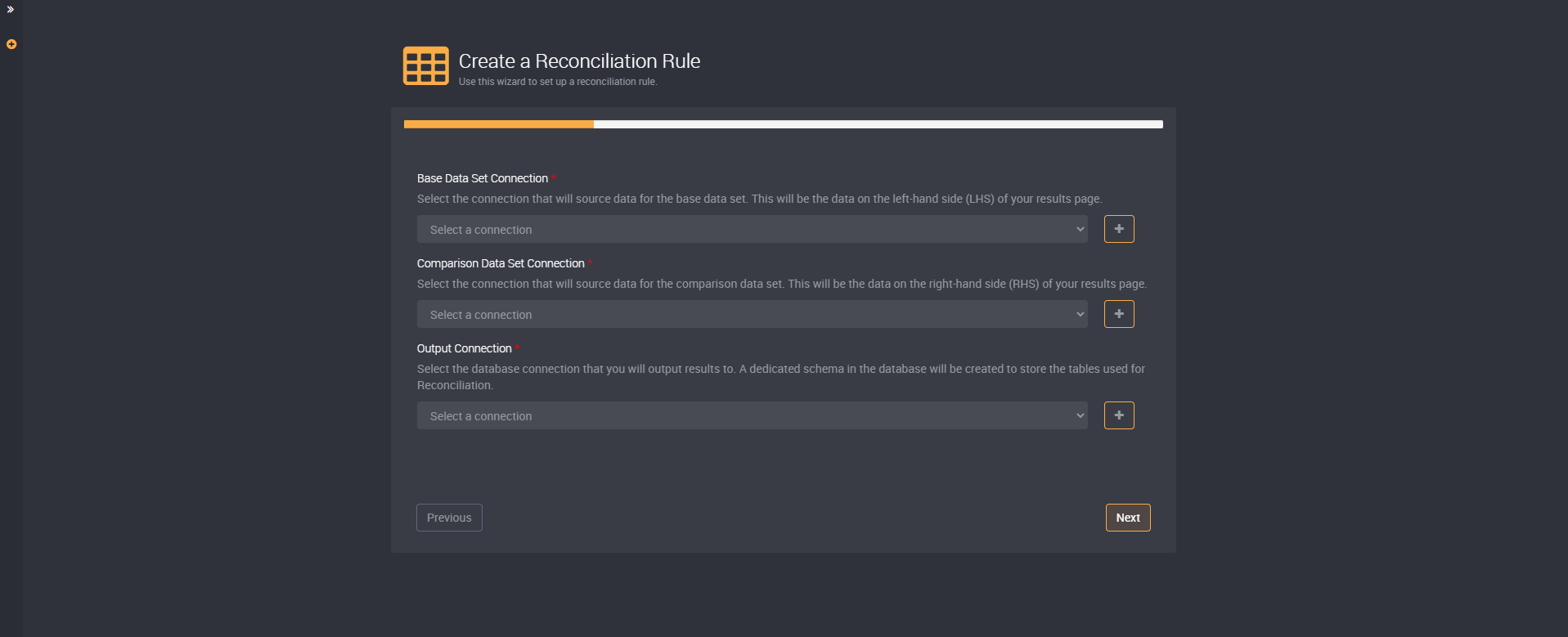
You will need to choose a base data set connection, a comparison data set connection and an output connection.
The ‘Base Data Set Connection’ will source data for the base data set, and will be the data on the left-hand side (LHS) of your results page. Any records in this data set that do not exist in the comparison data set, will have the status of ‘Left Orphan’.
The ‘Comparison Data Set Connection’ will source data for the comparison data set. This will be the data on the right-hand side (RHS) of your results page, and any records in this data set that does not exist in the base data set, will have the ‘Right Orphan’ status.
The ‘Output Connection’ is the database connection that the results will be stored. The reconciliation data of this rule will be available in the tables created in this database.
Data Set Names
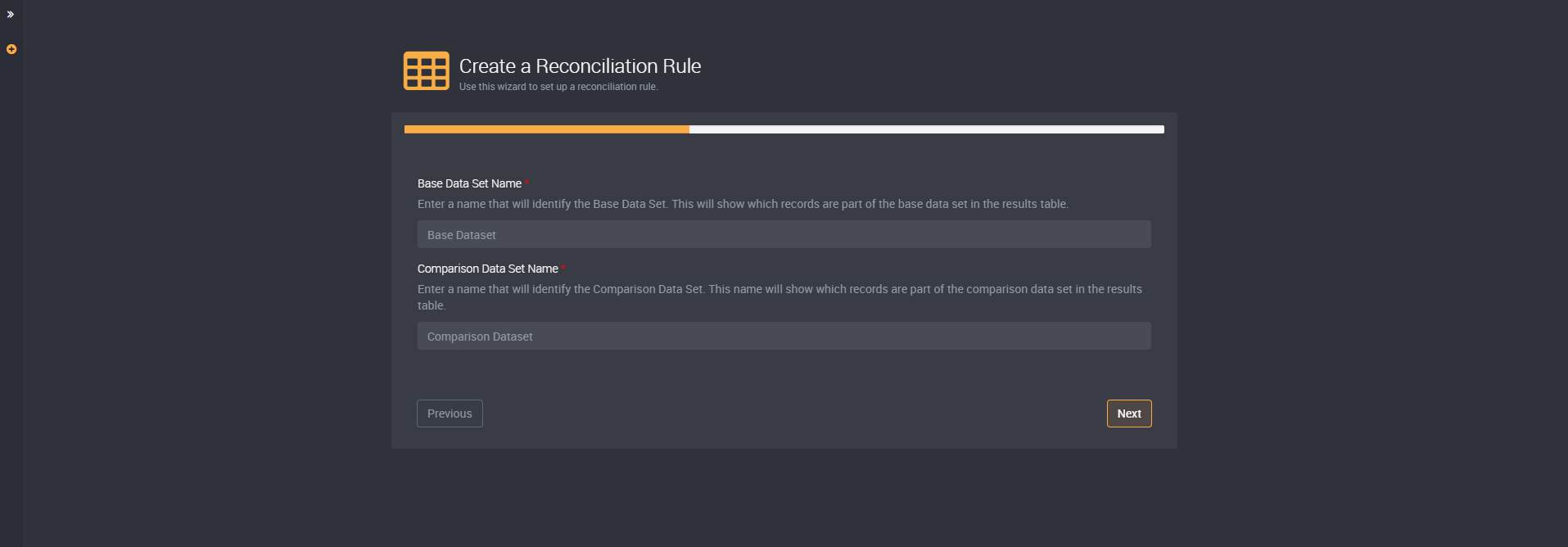
You can name the two data sets to differentiate the records of each dataset.
The ‘Base Data Set Name’ will identify the Base Data Set and will be above the records that are part of the base data set in the results table.
The ‘Comparison Data Set Name’ will identify the Comparison Data Set. It will be above the comparison data set on the right of the results table.
By default, it will be called ‘Base Dataset’ and ‘Comparison Dataset’, but you can change it to your preference with names that will easily identify the contents of each.
Query
You will need to provide two queries, one for the base data set and another for the comparison data set.
These queries will select the records that qualify for this rule’s criteria.
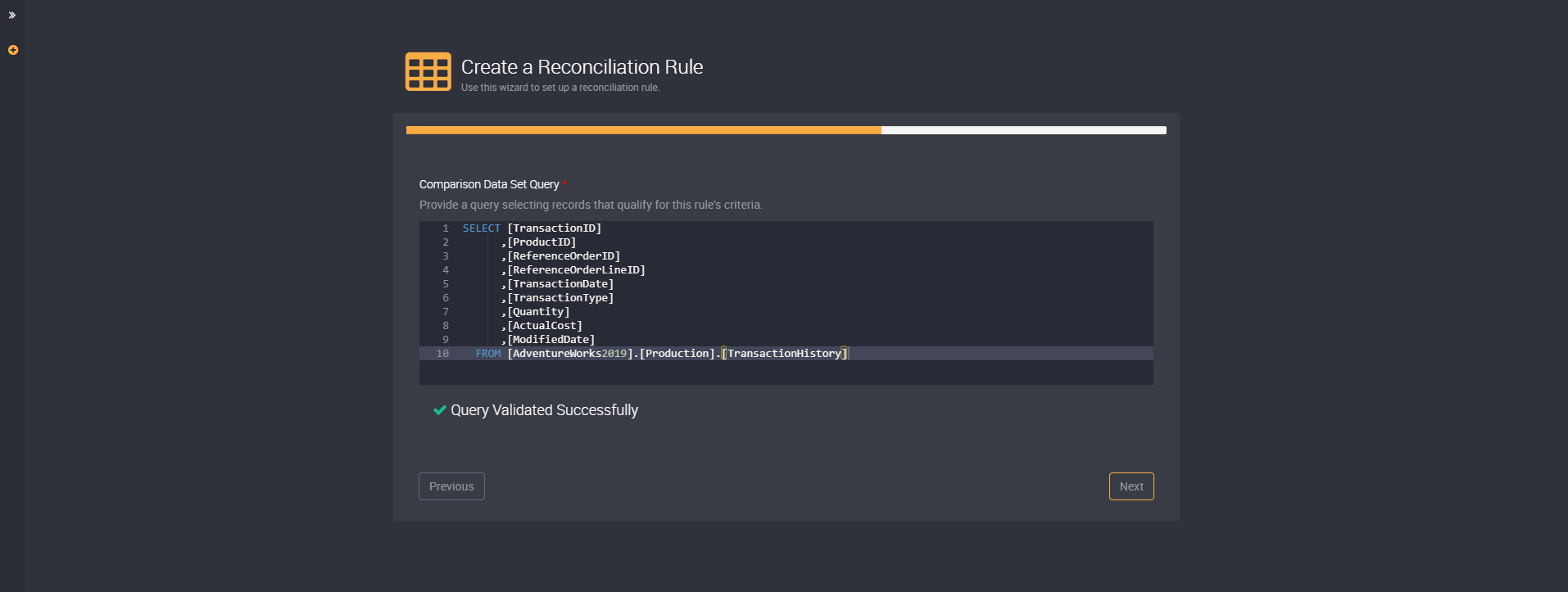
The Comparison Data Set columns need to match the Base Data Set columns in order to compare each record in both data sets. This includes both the data types, as well as precision and scale values, and names of the columns. If there are columns that do not match, there will be a warning below the query field that will list the columns that do not match in each data set.

You will next choose a key column, and can choose to create custom fields, before you can then run the reconciliation rule. For a guide on key columns and custom fields, please read more here.
Results
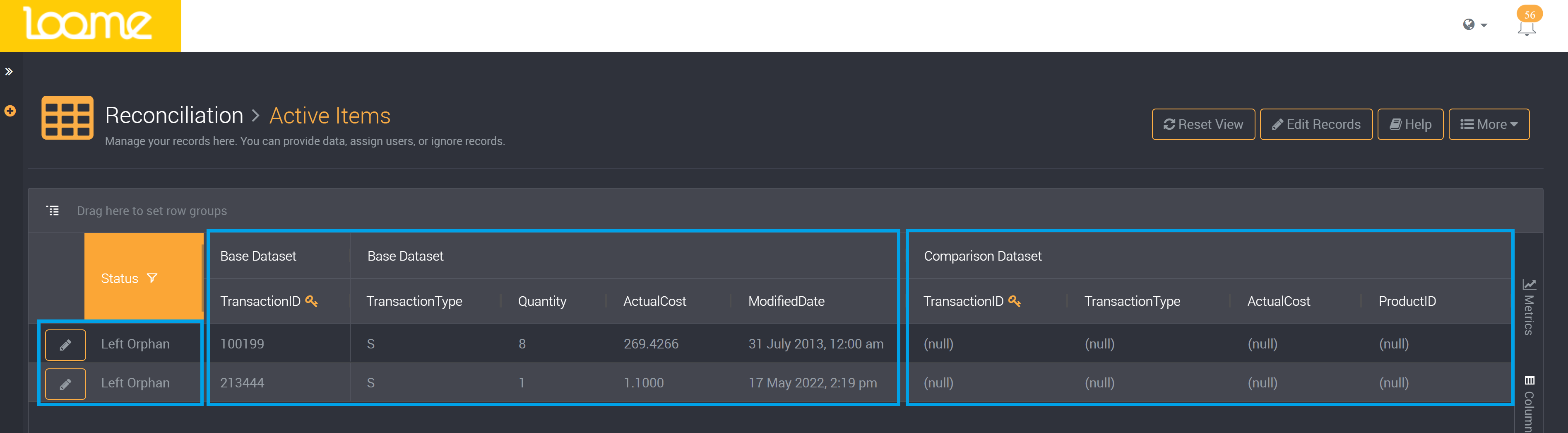
The results will display the base data set on the left and the comparison on the right of the table.
The status column on the left will show whether it is a mismatch, left orphan, or right orphan. These three statuses will be displayed by default if they exist in the data set.
As per other rules, you can view when the record was created, updated, and whether it is a new record on the left of a table.
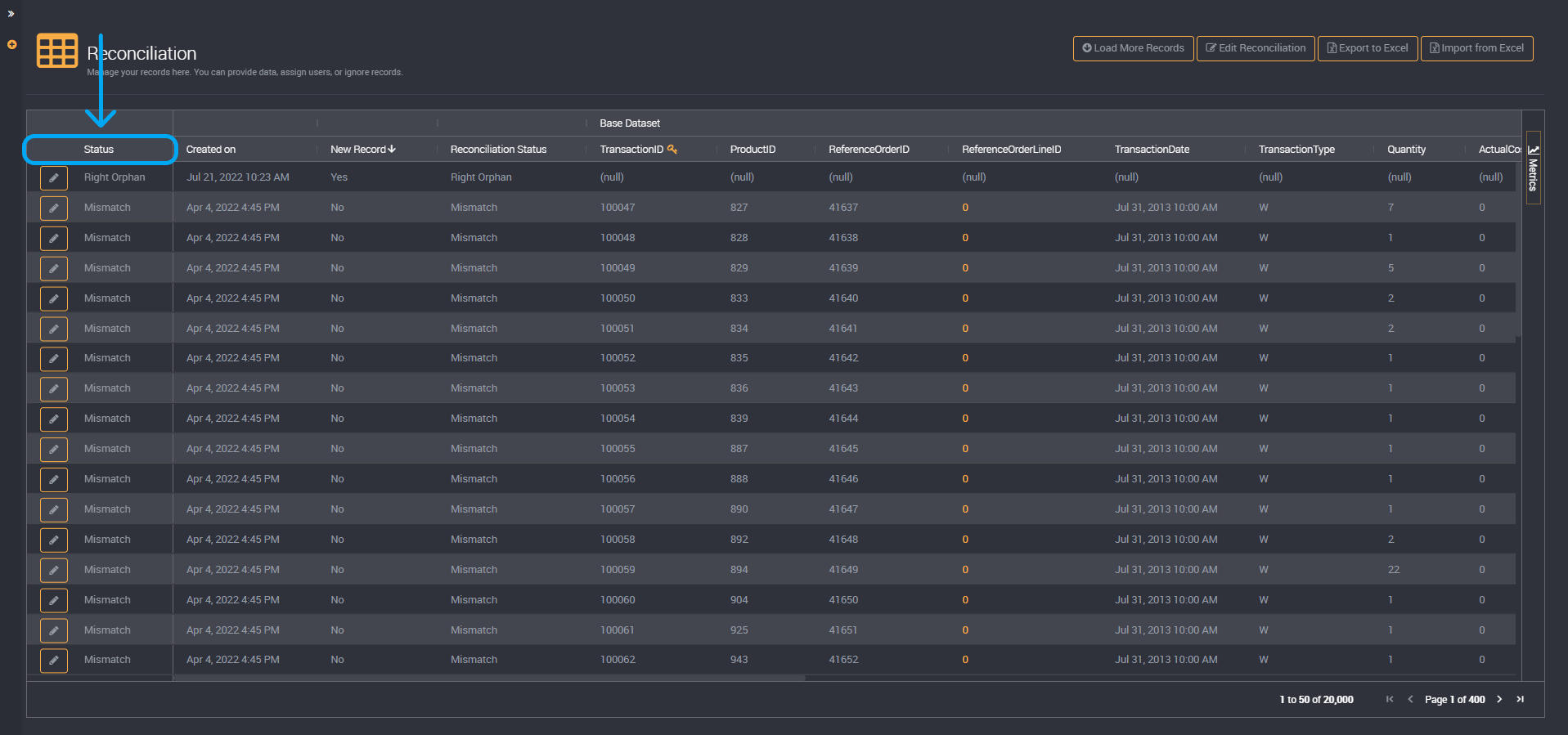
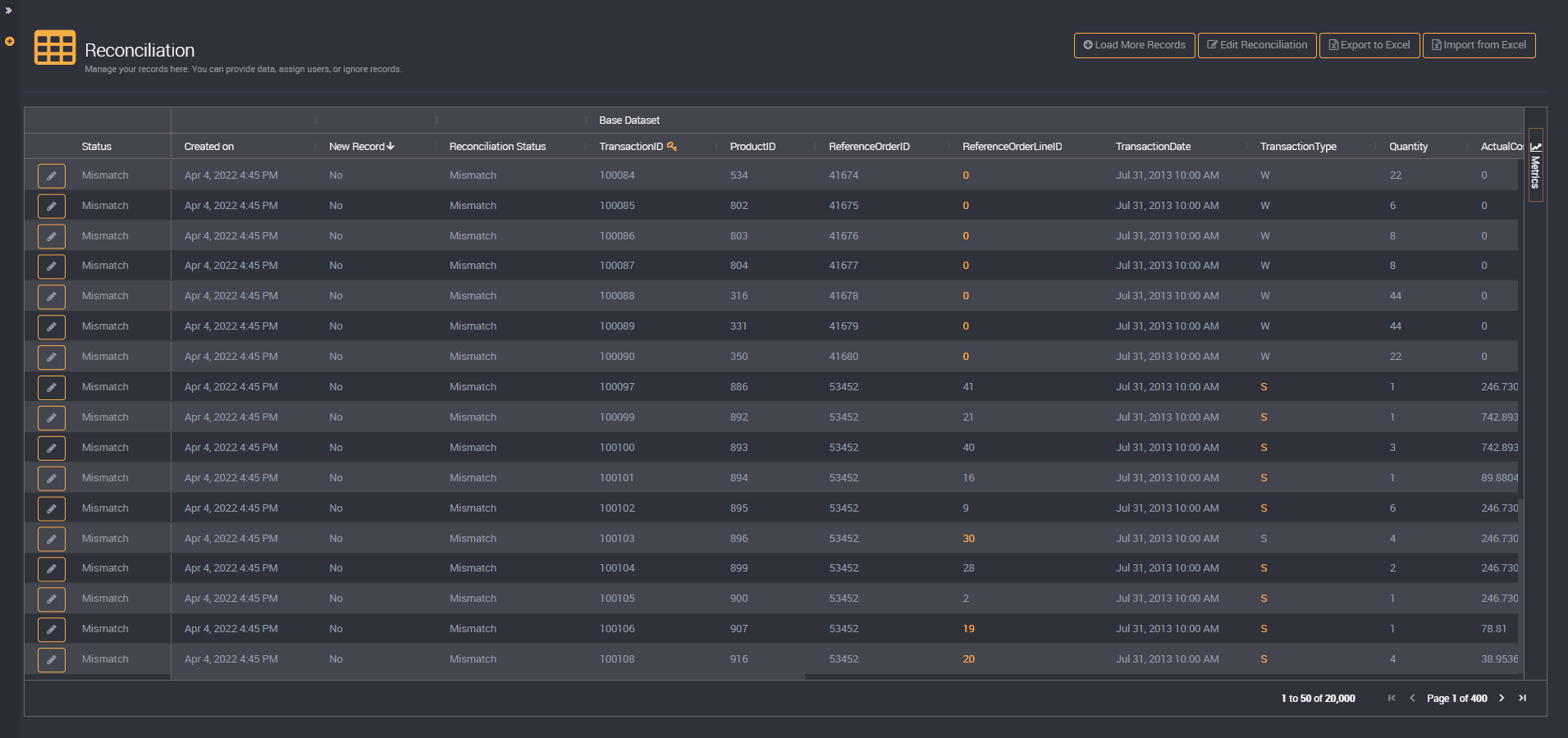
Mismatch:
In your two datasets, any mismatched values will be highlighted. For example, the same record in both data sets for product number 50 may have a categorization type of ‘W’ in the base data set but the type ’S’ in the other comparison data set. Both ‘W’ and ’S’ will be highlighted in this row and you can update your records and resolve which of the two is correct.
Left and Right Orphans
When a record exists in one data set but not in the other, it will be called a left or right orphan. Whether it is a left or right orphan depends on whether it is in the source or comparison data set.
A left or right orphan will have values from its data source in one data set and null values in the other data set.
Right Orphan:
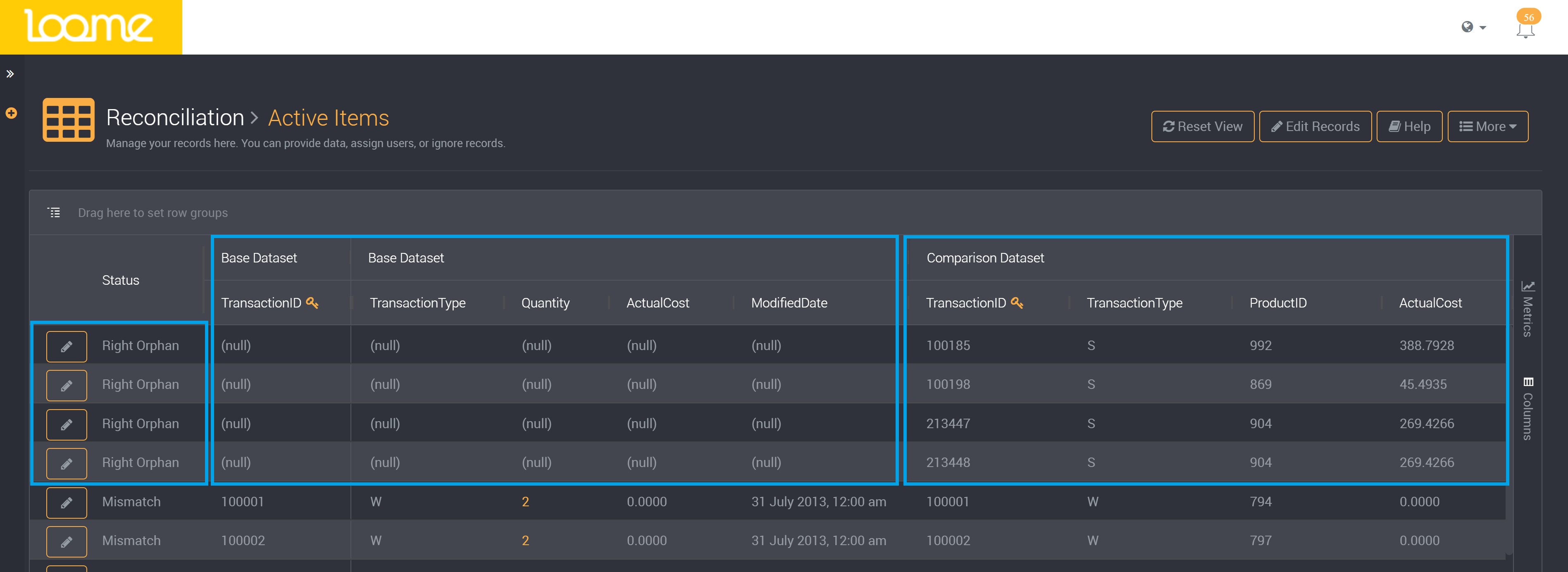
Left Orphan: